
[ChatGPT 용어 사전_001_정의]
ChatGPT : 챗GPT란 인공지능의 일종으로, 2022년 11월 OpenAI사에서 내놓은 언어 모델이다. 대량의 문자 데이터를 학습해 자연 언어의 생성과 이해, 문장 요약과 번역등의 과제를 수행할 수 있다. 챗GPT는 인간처럼 자연스러운 문장을 생성할 수 있기 때문에 대화와 문장 작성 등의 분야에서 폭넓게 활용되고 있다.
위 문장은 사실 'ChatGPT'가 작성한 것입니다. "ChatGPT란 무엇인지 전문 용어를 사용하지 말고 알기 쉽게 설명해 줘. 단 다음 말을 넣어서. 2022년 11월"라고 지시한 결과 생성된 문장입니다
[ChatGPT 용어 사전_002_기계 학습(Machine Learning)]
인공지능에 시행착오를 반복 시켜 올바른 결과가 노드와 노드의 연결(중요도 평가)을 서서히 변화 시키는 것을 말한다.
기계 학습은 자율 주행 자동차, 필기체 문자 인식 등과 같이 알고리즘 개발이 어려운 문제의 해결에 유용하다.
대부분의 기계 학습은 다수의 파라미터로 구성된 모델을 이용하며, 주어진 데이터로 파라미터를 최적화하는 것을 학습이라고 한다. 기계 학습은 학습 문제의 형태에 따라 지도 학습(supervised learning), 비지도 학습(unsupervised learning) 및 강화 학습(reinforcement learning)으로 구분한다.
디프 러닝(Deep Laerning)도 기계 학습의 범주에 속한다.
[ChatGPT 용어 사전_003_뉴럴 네트워크(Neural Network)]
인간의 뇌를 모방해 서 인공적으로 구현한 인공 신경 세포체의 네트워크. 인간의 뇌는 많은 신경 세포(neuron)로 이루어지고 신경 세포끼리 네트워크를 형성하는데 신경 세포끼리는 ‘시냅스(synapse)’라는 구조를 통해 다른 신경 세포의 정보를 주고 받는다. 뉴럴 네크워크는 이런 인간의 신경세포의 작용을 인공 신경 세포로 재현한 것이다.
인공 신경 세포는 여러 개의 인공 신경 세포로부터 입력을 받아 들여 그들 입력 값에 계산을 가한 값을 출력한다
[ChatGPT 용어 사전_004_디프 러닝(Deep Laerning, 심층학습)
컴퓨터가 스스로 학습하는 ‘기계학습’의 일종으로, 인간의 뇌신경의 메커니즘을 모방해 인공 신경 세포를 다수 사용해 층상 네트워크를 만들어 AI에게 학습 시키는 ‘뉴럴 네트워크’라는 방법을 발전 시킨 것이다.
디프 러닝은 ‘자연 언어 처리’ 분야에도 혁신을 불러 왔는데, 자연어 처리란 프로그래밍 언어가 아니라 사람 사이에 일상적으로 사용하는 말(자연 언어)을 컴퓨터에게 처리시키는 기술이다.
이때 자연 언어처리에서는 ‘언어 모델’을 사용해 문장을 생성하는데 언어 모델이란 인간의 언어를 이해하기 위한 일련의 프로그램(AI)이다.
언어 모델을 사용하면 어떤 단어의 다음에는 어떤 단어가 오기 쉬운지 예측이 가능해 진다. 이처럼 ChatGPT는 AI에게 대량의 문장을 읽어 들이게 해서 어떤 단어 다음에 어떤 단어가 오기 쉬운지 그 특징을 인식시킴으로써 원하는 결과물을 언어의 형태로 출력하는 인공지능인 것이다. 이때 활용되는 기술이 바로 디프 러닝 기술이다.
이미지 분석을 예로 들어 보면, 꽃을 촬영한 다수의 사진으로부터 AI 가 특별히 해바라기를 인식하는 메카니즘을 그림으로 나타내 보았다
디프 러닝에서는 인공 신경 세포를 ‘입력층’ ‘중간층(숨은층)’ ‘출력층’으로 나누어 이미지 정보를 분석한다(중간층은 다시 여러개의 층으로 나뉠 수 있다). 이처럼 많은 뉴럴 네트워크의 층을 사용하기 때문에 디프 러닝이란 이름이 붙게 되었다.
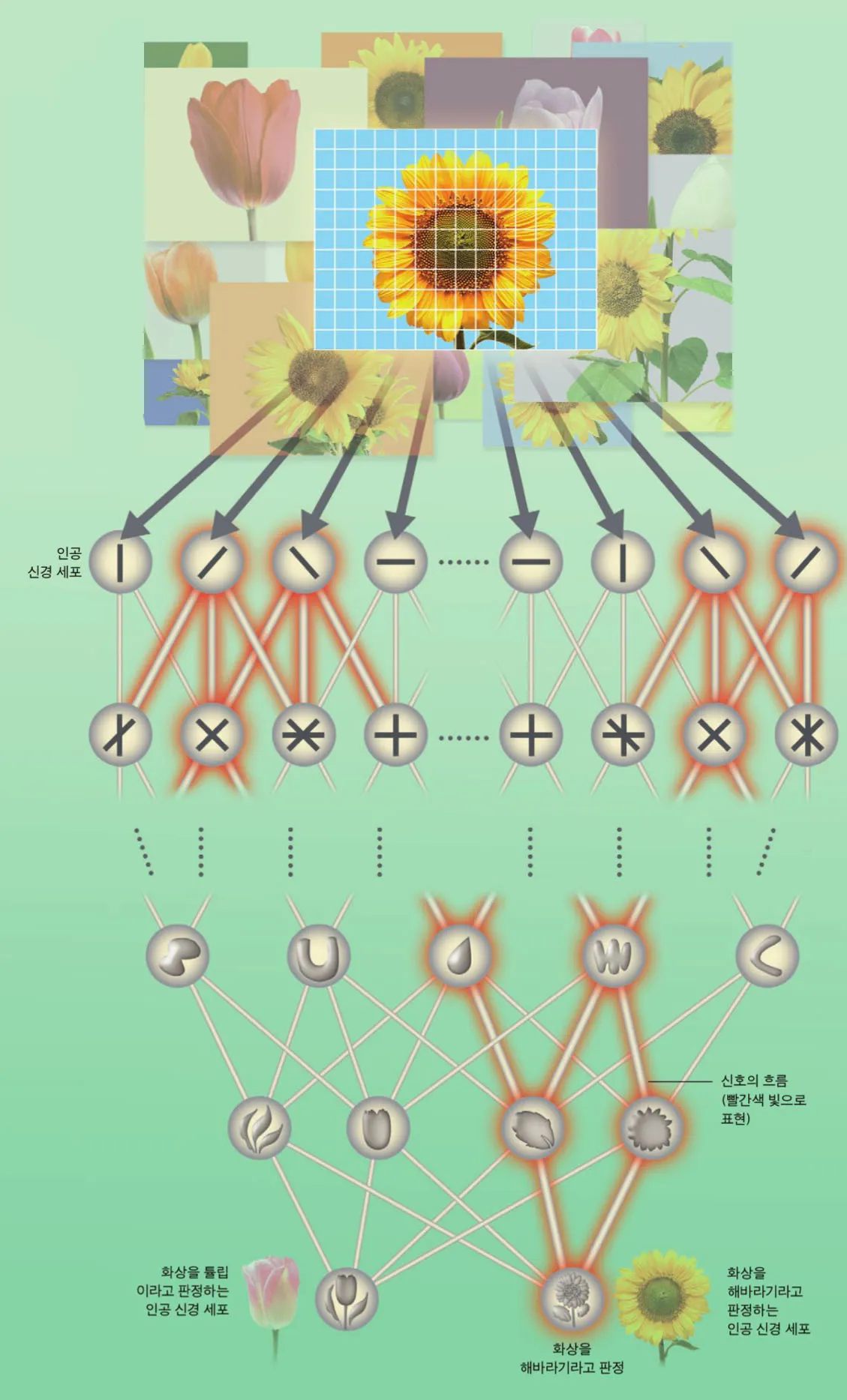
(1) 입력층 :이미지 정보(각 화소의 명암등에 관한 값)가 입력된다.
(2) 중간층(은닉층, 숨은층) : 많은 인공 신경 세포가 입력값 등에 따라 다음 층의 인공 신경 세포로 출력 신호를 보낸다. 이런 과정을 통해 이미지의 특징을 조금씩 파악해 간다.
(3) 출력층 : 식별한 특징을 바탕으로 주어진 이미지가 무엇인지를 출력한다. 이 예로 말하면 이미지가 튤립이 아니라 해바라기라고 출력한다.
[ChatGPT 용어 사전_005_트랜스포머(Transformer)]
단어를 수학적인 벡터(vector)로 변환하고 단어와 단어 사이의 ‘내적(內積)’을 계산함으로
써 단어(벡터)끼리의 거리를 측정해 문장을 이해하는 혁명적인 기술.
AI가 디프 러닝을 사용해 데이터의 특징을 추출한 경우, 추출한 특징 가운데 무엇이 도움이 될지는 목적과 문맥에 따라 달라진다.
이때 중요한 것은 학습하는 데이터의 어떤 특징에 ‘주의(attention)’를 기울이느냐 하는 것인데 그 주의를 기울이는 방법을 학습하는 메커니즘이 바로 셀프-어텐션(self-attension)이다.
이처럼 트랜스포머는 입력 데이터의 중요성에 따라 가중치를 부여하는 셀프-어텐션(self-attension) 기반 딥러닝 모델로서 인간의 주의(attention)를 모방한다.
다시 말해, 트래스포머는 수천억개의 문장과 문장 사이에서 단어와 단어 그리고 문장과 문장 사이에서 확률적인 관계를 분석하고 학습했기 때문에 폭넓은 문맥과 단어의 의미를 고려해 적절한 문장을 생성할 수 있는 것이다.
간단한 예를 들어, "나는 학교를 마치고 ?으로 갔다."라는 문장에서 ?에 해당하는 1음절 단어는 뭘까요? '집'일 것입니다. 이처럼 너무도 당연하다고 생각하는 건 우리의 삶의 경험상 집이란 단어가 주어진 문장의 문맥상 가장 가까운 단어이기 때문이지요. 트랜스포머의 원리도 이와 같습니다. 인간이 발간한 모든 책을 읽고 단어와 단어 사이의 상대적 친밀도를 기억하기에 일단 질문(문장)만 주어지면 그에 상응하는 단어와 단어가 술술술 나오면서 답변(문장)을 만들어 내는 것입니다. 이 세상 존재하는 모든 문서를 읽고 전부 기억하고 있으니 얼마나 말을 잘 하겠습니까? ^^
[ChatGPT 용어 사전_006_대규모 언어 모델(Large Language Model : LLM)] :
GPT처럼 대량의 문장 데이터를 학습해 인간과 같은 수준의 언어 능력을 획득한 AI로서 수많은 파라미터(보통 수십억 웨이트 이상)를 보유한 인공 신경망으로 구성되는 언어 모델이다.
이러한 모델은 대규모 데이터셋(data-set)을 통해 학습되며, 언어를 이해하고 생성하는 능력을 가진다. 대규모 언어 모델의 주요 특징은 방대한 양의 텍스트 데이터로부터 언어의 구조, 문법, 의미 등을 학습하여 인간처럼 자연스러운 언어를 생성하거나 이해할 수 있다는 점이다.
대규모 언어 모델은 다음과 같은 과정을 거쳐 학습된다.
•데이터 수집: 인터넷, 서적, 뉴스 기사 등 다양한 출처에서 대량의 텍스트 데이터를 수집한다.
•학습: 이 데이터를 사용하여 모델이 언어의 패턴을 인식하고 학습할 수 있도록 한다. 이 과정에서 모델은 단어, 문장, 문맥의 의미를 파악하게 된다.
•조정 및 최적화: 모델의 성능을 향상시키기 위해 추가적인 조정과 최적화가 이루어진다.
대규모 언어 모델은 자연어 처리(NLP) 분야에서 중요한 역할을 한다. 이들은 기계 번역, 자동 요약, 질문 응답 시스템, 챗봇, 텍스트 생성 등 다양한 분야에서 활용되고 있다. 또한, 이러한 모델은 지속적으로 발전하고 있어 앞으로 더 많은 분야에서 중요한 역할을 할 것으로 예상된다.
2018년—> 최초의 GPT인 GPT-1 공개. 2019년—> GPT-2공개. 2020년—> GPT-3공개.
2022년 11월 30일—> GPT-3.5 2023년 3월 15일 —> GPT-4 공개
대규모 언어모델이 있다면 소규모 언어 모델(SLM)도 있을까? —> 있다!
[ChatGPT 용어 사전_007_소규모 언어 모델(Small Language Model)] :
이것은 LLM에 비해 상대적으로 적은 양의 데이터로 학습된 언어 모델로서 학습 데이터와 파라미터 수가 적으며, 그 결과 더 제한된 언어 처리 능력을 가진다. LLM이 방대한 데이터를 바탕으로 다양한 언어적 상황에 대응할 수 있는 반면, SLM은 특정 작업이나 좁은 범위의 언어 이해에 최적화되어 있습니다. LLM은 더 광범위한 언어적 뉘앙스와 맥락을 파악할 수 있지만, SLM은 그보다 특정화되고 효율적인 작업에 적합하다.
적용 사례는 다음과 같다.
•챗봇: 특정 기업의 고객 서비스를 위한 챗봇은 일반적으로 한정된 주제와 질문에 대응하기 위해 설계된다. 이런 경우, SLM이면 충분하며, 이는 특정한 업무 지식이나 고객 질문에 특화되어 효과적인 대응이 가능하다.
•특정 언어 처리: 특정 언어나 방언에 특화된 언어 모델이 필요한 경우, SLM은 그 특정 언어에 최적화되어 더 정확한 결과를 제공할 수 있다.
※ SLM 적용 사례 : 삼성 갤럭시 S24 의 실시간 번역 기능등.